We tried Modal, Cloudflare Containers, and Sprites before building our own persistent container service
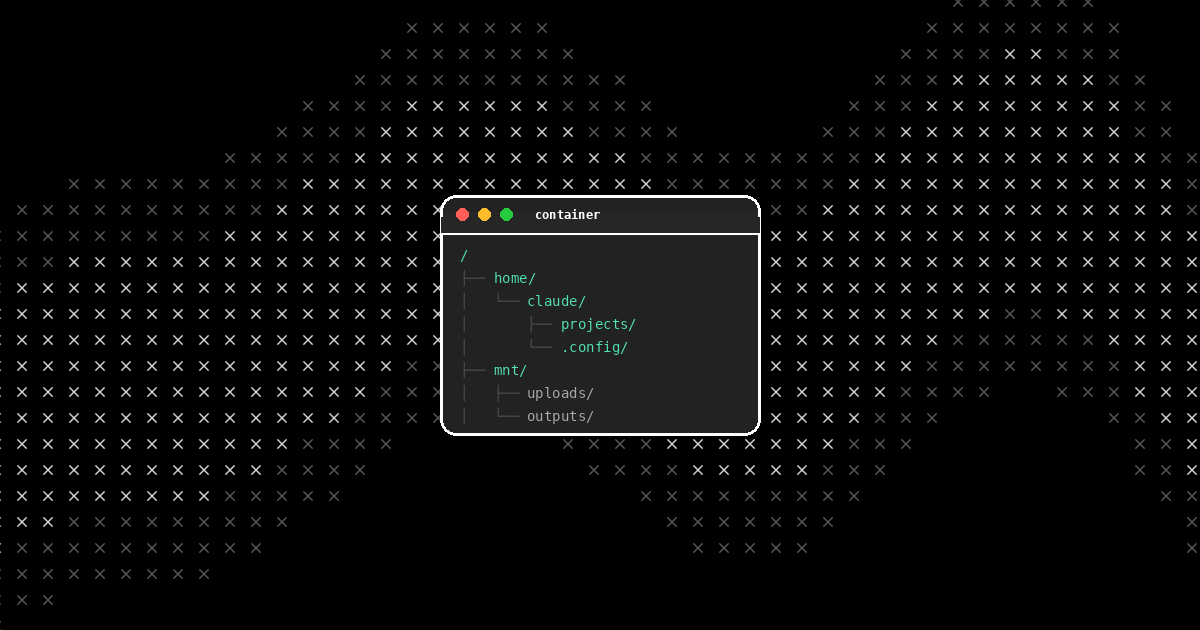
Every user on camelAI gets a persistent computer. A real Linux environment with storage, dependencies, and project state that survives across sessions. When you come back tomorrow, your files, databases, and apps are exactly where you left them.
This is the core promise of our product, and for over 2 months, we couldn't make it work.
We tried Modal, Cloudflare Containers, and Sprites. We looked at E2B, Daytona, Vercel Sandbox, and even OpenAI's container tool. None of them fit. So we built our own container service in a week, and it was simpler than any of us expected.
I'm Illiana, and I run camelAI with my co-founders Miguel (CTO) and Isabella (COO). This is the story of the failed attempts trying to use existing SaaSs and the stack that's working well in prod today.
What We Needed
-
Persistence. The entire filesystem needs to survive across sessions. Not "persist this one folder."
-
Performance. Our agent installs heavy JavaScript dependencies, runs data analysis, deploys full-stack apps. The filesystem and compute have to be fast.
-
Reliability. If a user's container disappears, they lose their work. Unacceptable.
-
Programmable from JavaScript. Our backend runs on Cloudflare Workers. Everything is TypeScript. We can't drop into Python to manage containers.
That last requirement eliminated more options than you'd think.
Modal: Fast to Start, Hard to Stay
Modal was the first service we tried. The onboarding experience was smooth, and you can get something running quickly. But Modal's interface is a Python library. Our entire backend is TypeScript running on Cloudflare Workers, and introducing Python as a dependency for a critical part of our infrastructure wasn't something we were willing to do.
Beyond the language mismatch, persistence was the real problem. Modal had multiple storage options, most of which were unusable for us. The one that looked closest to what we needed (Volumes V2) was labeled beta and still wasn't exactly what we needed. For a feature this central to our product, building on a beta storage layer wasn't an option.
We moved on.
Cloudflare Containers + JuiceFS: The Creative Hack
Since our entire stack already runs on Cloudflare, their container service was the natural next choice. Cloudflare Containers were new at the time, and they've improved since, but when we tried them they were designed for ephemeral workloads. Persistence meant checkpointing specific folders at intervals, not the seamless, always-on filesystem we needed.
So we got creative. We'd read a blog post from Fly.io about Sprites that described a storage architecture modeled after JuiceFS, a distributed filesystem that splits file data into chunks on object storage. We figured: what if we ran JuiceFS on Cloudflare Containers, backed by an R2 bucket?
It worked. Sort of.
JuiceFS is painfully slow for high-volume file operations. When you're installing thousands of JavaScript packages, each one a separate file write, the overhead is brutal. Install times went from low single-digit seconds to minutes.
At first, we fought this. We switched to Yarn Plug'n'Play, which replaces traditional node_modules with large zip files. This dramatically reduced the number of individual file operations. It helped. But there were still too many places where filesystem performance mattered, and the CPUs on Cloudflare Containers weren't fast enough for our compute-heavy workloads.
Then came the memory leaks. Containers would gradually slow and eventually crash. Our JuiceFS setup had reliability issues. Files sometimes wouldn't persist correctly. The whole thing was getting too complex, and we were stacking hacks on top of hacks.
We needed something designed for persistence from the ground up.
Sprites: So Close
We'd actually wanted to try Sprites by Fly.io earlier in the process. We'd been eyeing them since reading the blog post that inspired our JuiceFS attempt, but Sprites was labeled as beta, and we'd just been burned by building on beta infrastructure with Cloudflare Containers. After that experience failed, we were desperate enough to try.
Sprites was impressive from the moment we got it running. The machines were fast, responsive within a second, with noticeably better hardware than anything we'd used before.
But Sprites isn't a traditional container service. You can't just hand it a Docker image and spin up a fleet. You spin up a Sprite, install your dependencies inside it, and then that Sprite is provisioned. To work around this, we pre-provisioned a pool of Sprites so new users would have one ready when they signed up.
Updating software on existing Sprites was worse. We had to iterate through every single Sprite, wake it up, run a migration command, and move to the next one. No support for image-based deploys or atomic rollouts.
We dealt with all of that because the performance was genuinely great. And then the containers started vanishing.
Technically, the files weren't lost. The Sprite itself had become unreachable. Sometimes it would come back online much later. Sometimes it wouldn't, at least not within any timeframe we could wait for.
We went to the Sprites forums, found other people reporting the same thing. The team at Fly.io is doing ambitious work, but the reliability isn't there yet for a production use case.
The Turning Point
At this point, we were three weeks past the date we'd planned to start onboarding beta users to a stable product. The beta users who were on the unstable build were mostly friends or a few customers we'd accidentally shared a link with.
Morale was low. Nothing was reliable enough.
I asked Miguel, "why can't we just build this ourselves?"
Miguel was frustrated. Partly because he felt I didn't appreciate how much work goes into container infrastructure, and partly because he wasn't down for building it from scratch.
Then we asked ourselves, what would the MVP be?
We realized we don't need to rebuild Modal. We don't need multi-region orchestration or elastic scaling or a self-service API. We need containers that are persistent, fast, and reliable for our own product. That's a much smaller problem. This was doable.
It also helps that we have a pile of cloud credits we'd been spending almost entirely on LLM costs. We could provision a large server instance and not worry about optimizing for cost efficiency right away.
What We Actually Built
The stack is simple:
-
A VM instance on a cloud provider (we use Azure because of credits, but any provider works)
-
Docker + gVisor for container isolation. gVisor is Google's open-source container runtime that provides kernel-level isolation. Each container gets its own sandboxed kernel. The alternative is Firecracker (AWS's microVM engine, used by Lambda), but most VMs can't run Firecracker due to nested virtualization requirements. gVisor has a small performance overhead, but we haven't noticed it in practice.
-
A large network-attached disk mounted to the VM, shared across all containers
-
XFS with project quotas to give each container a fixed storage allocation on the shared disk. XFS's project quota feature lets you enforce storage limits on directory trees. Each container gets up to 100GB, and they can't exceed it.
That's it. Each container's home directory lives on the shared disk. Persistence isn't a feature we had to engineer. It's just how files on a disk work.
We built it in about a week. Every persistent issue (the crashes, the vanishing files, the slow filesystems, the memory leaks) was gone immediately.
What This Costs
We're running a large instance because we have the credits and we need to support heavy concurrent workloads. Our agent runs Claude Code, installs large dependency trees, does intensive data analysis, and deploys full-stack applications.
But if your use case is lighter, you could comfortably run 50–100 lightweight containers concurrently on a ~$200/month cloud instance, or a couple dozen doing heavier work. gVisor, Docker, and XFS are all free and open source.
TL;DR
We spent over 2 months evaluating and integrating container services. Modal required Python and didn't fit our persistence requirements, Cloudflare Containers also couldn't persist reliably, and Sprites kept losing machines. None of them were designed for our needs (always-on, fully persistent, fast, reliable, and programmable from a Cloudflare Workers backend).
The services we tried aren't bad, but when you're buying a service, you're buying the lowest common denominator of everyone's requirements, or adapting something designed for a different problem.
Building it ourselves took ~1 week and gave us exactly what we needed. No persistence hacks, no filesystem workarounds, no praying that a beta feature would stabilize. Just a VM, some containers, and a big disk.